Past fast Fourier transform (FFT) circuit architectures have remained relatively unchanged, being either "memory-based" or "pipelined". Memory-based designs are typically slow and pipelined designs, which are obtained from different permutations of the signal flow graph and mappings thereof, lead to inherent circuit irregularities which compromises functionality and performance.
Centar's design is also memory-based, but is architecturally very
different than traditional memory-based approaches as can be seen below.
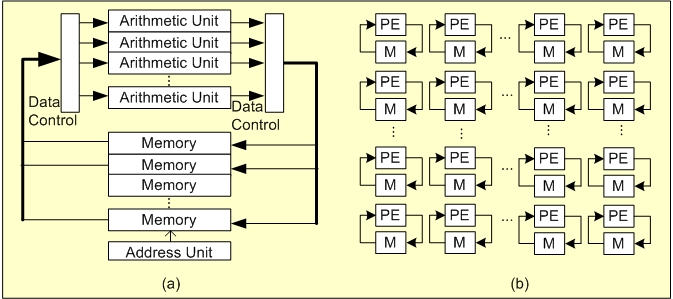
Here a traditional high-performance memory-based design (a) is shown to
consist of (usually) large arithmetic units, where typically butterfly
computations are performed, connected to an array of memories. The
difficulty in such designs is to sequence data to/from the memories in such
a way that available bandwidth is maximized. Alternatively, the Centar's
circuit does the same thing, but at a finer level of granularity. From (b)
it is seen to consist of many very small processing elements (PEs), each
containing a multiplier/adder and a few registers. Each PE reads and writes
to a typically small memory and aggregate bandwidth is limited only by the
number of PEs. This scalability means that high bandwidths, and thus
performance, are achieved by simply increasing the array size. It is
much more difficult to do the same for traditional memory based designs based on (a). As a result:
- Throughputs are much higher than other FFT circuits that use equivalent or more hardware resources due to
- Very high clock speeds (>500MHz in 65nm FPGA technology) that result from interconnects which are entirely local, reducing parasitic routing capacitances
- A high degree of data parallelism
- Less than the usual N cycles per DFT block (algorithmic improvements)
- The circuit is programmable, a major difference when compared to traditional high performance parallel FFT designs. A non-power-of-two circuit can be programmed by entering parameter values into a single ROM memory and the number of different DFT sizes that can be supported is only limited by the size of this parameter memory.
- Dynamic range is higher than other fixed-point or block floating point FFT designs for a given word size because the computation is done using a combined block floating point and floating point architecture, e.g., a 1024-point 16-bit (in/out) FFT provides a dynamic range of 94db.
- For non-streaming designs the latency can be approximately equal to the inverse throughput rate. In other words the time it takes to compute the first DFT in a series of DFT computations is roughly equal to the time it takes to compute each successive DFT. This is significant because most fast pipelined FFT engines have “startup” times of ~N cycles, where N is the transform size, making the first DFT computation twice as long.
- Faster transforms can be implemented without architectural changes by increasing the array size along one dimension or duplicating the array structure
- The same circuit architecture can directly perform small 2-D DFTs as well as 1-D DFTs.
- Interconnects are entirely local, significantly reducing parasitic routing capacitances to keep power dissipation low.
- The inherently linear structure of the FFT circuit is an excellent architectural match for the recent generation of high density FPGAs like the Vertex series from Xilinx and the Stratix series from Altera. Both of these chip types feature architectures also characterized by linear arrays of hardwired elements such as memories and multipliers.
- Small DFTs (less than 128-points) can be performed as efficiently as large FFTs.