
Algorithm Types
Algorithms must be of a type that can be represented by sets of iterative or recursive statements with affine dependencies, each defined over a common set of indices. (The user index space I is that of the “looping” variables used to describe the problem.) Formally, this means that problems will be of the form
where f,g represent the functional variable dependencies, where the operator represents a commutative and distributive operator (
,
, max and min) and where the affine “indexing” functions are
Here, I j is a vector of indices common to each statement, xi is one of n algorithm variable symbols, and A/a and B/b are integer matrices/vectors. All assignments in the system of iterative equations must not involve a reuse of a variable, where a set of specific indices associate a unique variable xi[i,j,k,...], with the algorithm symbol xi.
Using this formalism, an algorithm for matrix-matrix multiplication, C=DxE, where C,D and E are NxN matrices, can be described by the statement:
where I=[i j k]. The affine indexing matrix associated with the elements of c of matrix C above are
and similarly for the matrices D and E.
Input Language:
The high level language used to express this formalism is a small subset of the Maple™ language, a generic Algol derivative, which gives the user the option of actually running the algorithm using the Maple environment directly. The Maple equivalent of the matrix-matrix multiplication above is
for i from 1 to N do
for j from 1 to N do
for k from 1 to N do
c[i,j] := add(d[i,k],e[k,j], k=1..N);
od;
od;
od;
In the code above Maple interprets the loops in the traditional way that serializes the computation. However, SPADE only uses them to determine the ranges of the three indices, I=[i,j,k]. SPADE can parse multiple arithmetic assignment statements within “for” loop constructs, which can also contain “if/elif/else” conditionals. Maple operators such as
are the set of functions allowed by SPADE.
Transformation Outputs
Each algorithm symbol in an algorithm specification, as for example c,d and e in the matrix-matrix algorithm, has dependencies specified by some or all of the indices, I. The purpose of SPADE is to provide transformations, T, that map these indices to a “space-time” representation. A space-time representation associates one dimension with time and the others with space, where the spatial view is that of an array of abstract elemental processors (PEs) that have the ability to perform simple arithmetic and communicate with their nearest neighbors. In a custom FPGA or ASIC hardware implementation these PEs respresent small, elemental processors controlled by a simple finite state machine.
The dimensionality of I will typically be the same as space-time. That is, if the index vector I has a dimension of three, then space-time will contain two spatial dimensions along with a time dimension.
For each allowed value of time, all needed computations in all PEs in the spatial plane can be done simultaneously. The basic execution cycle consists of two steps: first there is a local movement of data between adjacent PEs, followed by a computation step in some or all of the PEs. The algorithm latency is the total number of these basic steps needed to compute the entire result.
The transformation, T, is itself affine, consisting of a linear part and an offset. For example, the transformation of the matrix-matrix multiplication algorithm symbol c would be
where Tc is an integer matrix and tc is a vector offset. The matrix-matrix mapping solution generated by SPADE would then require T(d) and T(e) as well.
The transformation T can be thought of as consisting of two parts, one that determines the time or scheduling of a particular arithmetic operation and the other that specifies where in the spatial plane the operation takes place. That is writing T as
means that a variable x[It] defined by indices of the column vector, I, would execute at a time Λx(AxI+ax)+γx, where Λx is a row vector and γx is a scalar, and at a position Sx(AxI+ax)+sx in the spatial array, where Sx is a matrix with a number of rows equal to the dimension of the spatial array and sx is a vector.
Intermediate Variables
Sometimes it is necessary to introduce “intermediate” algorithm symbols to simplify the problem solution. Therefore, a listing of these variables and their associated transformation matrices is also an output of SPADE. For the matrix-matrix multiplication problem, the parser reinterprets the code as
for i from 1 to N do
for j from 1 to N do
for k from 1 to N do
w[i,j,k] := d[i,k]*e[k,j];
c[i,j] := add(w[i,j,k], k=1..N);
od;
od;
od;
where the intermediate symbol, w, is defined in terms of d and e. This step is done automatically with no input from the user.
Elimination of Global Data Movement
A key characteristic of the architectural mapping solutions generated by SPADE is that the mapped algorithm computations are usually “localized”. That is, there are no global broadcasts or “fan-in” of data needed. All data moves locally from one PE to another in such a way that it is always available at the PE where it is needed.
In order to specify how this is done, it is necessary to list all the dependencies in an algorithm. If at a particular time step, t, variable y[t ,px,py] depends upon variable x[t-1 ,px,py-1], then the value of x must be propagated in the direction [1,0,1] in space-time before time t. For each dependency in an algorithm SPADE automatically generates this localization information for the mapping solution.
In the matrix-matrix multiplication example above, the dependencies are
where, “→” means “depends upon”. Therefore another output of SPADE for this example would be a three element vector containing the propagation directions for the data flow associated with each of these three dependencies. (SPADE’s localization method only allows a one dimensional flow of data for each dependency.)
Graphical Output:
The transformations that map variables from the algorithm indices to space-time indices can be seen directly from a graphical views of space-time. SPADE will automatically generate these graphical views.
Each algorithm symbol in the algorithm description is mapped separately into space-time by a transformation matrix, T. A symbol in the algorithm description with one/two/three indices, would be described by a line/polygon/polytope in space-time, respectively. All the variables pictured together, provide a complete view of the spatial and time dimensions of the parallel algorithm execution model. 3-D views can be rotated real-time to better see variable placement and dependencies.
There are three different types of graphical outputs, one for 2-D space-time and two for 3-D space-time. The graphical output for 2-D space-time provides complete information on the flow of data and variable mappings all in one picture. For the 3-D space-time output there are two graphical outputs, an overall view of algorithm mappings into space-time and a corresponding projection of variable space-time extent onto just the spatial coordinates. The 2-D space-time projection shows the flow directions of data as well. Figure 1 displays a space-time mapping output for matrix-matrix multiplication and the corresponding spatial view only is shown in Figure 2. The variables c, d, e, and w correspond to those in the code above.
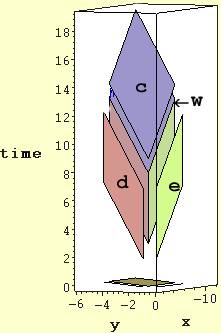
Figure 1. Matrix-matrix multiplication space-time mapping graphical output.
An outline of the projected spatial view is shown beneath the figure.

Figure 2. Matrix-matrix multiplication spatial only graphical output. The arrows
correspond to the flow of data between the variables c, d, e and w.