Introduction
To compute a transform of size N, the traditional “row/column” approach to compute the DFT is used. This factorization assumes the transform size N can be written N=N1*N2 and requires computation of two sets of smaller DFTs, N2 transforms of length N1 (referred to as “column” transforms) and N1 transforms of length N2 (referred to as “row” transforms). The N1xN2 “DFT matrix” X contains input samples x1,x2,…,xN2 on row 1, xN2+1,xN2+2,…,x2*N2, on row 2, etc. In between column and row transforms it is necessary to multiply each of the N points by the usual twiddle factor, WNi,k, i=0,1,..,N1-1, k=0,1,..N2-1. After the row transforms the DFT output Z resides in the matrix in column major order.
To compute the row and column DFTs, a new matrix formulation is used. For this each column and row DFT of size M (M=N2 for the row DFTs and M=N1 for the column DFTs) is further decomposed as M=N3*N4=N3*b. It can then be shown that the DFT of M can be computed by the expressions
Yb=WM•CM1Xb
Zb=CM2Ybt
where “b” refers to the value of N4 or “base”. Here Xb is an bxN3 input data matrix (M values) and the DFT output Zb is a bxN3 matrix (M values). Also, WM is a small N3 x N3 coefficient matrix used in an element-by-element multiply and CM1,CM2 are arrays of bxb radix-b butterfly matrices.
For all power-of-two circuits the base b is set to 4 so that elements CM1,CM2 contain the only the elements {1,-1,j,-j}. For non-power-of-two circuits the base must be large enough to include all factors of the desired transform size.
Architecture
An abstraction of the architecture (Fig. 1) shows that it consists of two bxb processing element (PE) pipelined or "systolic arrays" connected by a bx1 array of complex multipliers. Each PE in the left-hand-side (LHS) and the right-hand-side (RHS) systolic arrays contain a few registers, multiplexors, two real adders, and miscellaneous logic as shown in Fig. 2. Additionally, each PE in each systolic array has access to a small dual-port RAM, to which RHS PEs write and LHS PEs read. The systolic matrix-matrix multiplications are carried out using well known mappings of signal flow graphs to PE arrays. FFT input data in Xbc are all fixed-point n-bit 2’s complement words. The FFT computation proceeds in two basic steps as described below.
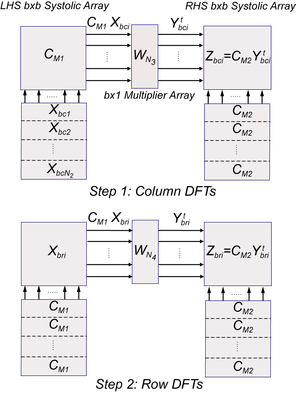
Fig. 1. Systolic processing flow for column and row DFTs. Subscript “c” and “r” refer to computing column and row DFTs of the N1xN2 DFT matrix.
Step 1: Column DFTs
An input buffer feeds the LHS SA with column data Xbci, i=1..N2, of the N1xN2 DFT matrix, each array of column elements organized as an M=N1=bxN3c matrix. Also, each PE in the bxb LHS systolic array contains an element of the bxb matrix CM1. The systolic matrix-matrix multiplication results CM1 Xbci then flow out of the LHS systolic array through the multiplier array shown in Fig. 1 where the coefficient multiplication by WM, stored in ROM, produces Ytbci. A second systolic matrix-matrix multiplication is then performed by the RHS systolic array with inputs Ytbci from the left and CM2 from the bottom (one CM2 matrix per column Xbci), producing the results Zbci, which are stored in a distributed fashion in the RHS PE RAMs and become the Xbri for row DFTs in Fig. 1 Step 2 after the twiddle multiplication by WNi,k.
Step 2: Row DFTs
The processing in this step with M=N2=bxN3r is often identical to that for the column DFTs with two exceptions. First, there is a juxtaposition of the CM1 values with the Xbri row inputs. In this case the row Xbri values are retrieved from the PE internal RAMs, while the CM1 values now flow into the LHS SA from the bottom. Second, the Zbri FFT outputs are stored in a separate RAM output buffer.
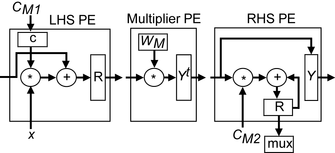
Fig. 2. Functionality of PEs in LHS and RHS arrays of PEs.
By choosing a SA size along with appropriate values of N1, N2, N3, and b, there are few restrictions on target transform sizes, hence the circuit is fundamentally programmable. The benefit of a programmable circuit is that the computational SA hardware can be highly optimized and then reused with different control circuitry to do many different computations. The SA size is chosen so that throughput requirements are met.