
Introduction
Centar has developed a unique non-power-of-two FFT architecture that simultaneously provides for high performance, yet is still programmable. This is a significant improvement in state-of-art because fast, mixed-radix FFT circuits are in difficult to design due to control complexities associated with irregular signal flow graphs, the need to support multiple butterfly sizes, and non-uniform scaling/word growth issues. Adding a requirement that transform sizes be selectable at runtime, imposes a further twiddle storage memory burden and compounds the control issues. Programmable designs are a natural approach to avoiding complexity, but are inherently slow.
Centar’s new architecture derives performance from an array of simple pipelined processing elements (PEs), each of which contains only an adder, a multiplier, registers and some miscellaneous logic. A simple control unit manages data flow to and from this array so that butterflies of different sizes can be systematically computed. A single ROM memory holds the parameters that determine the specific factorizations and execution orderings used for loop index ranges in the verilog HDL coded control modules. Consequently, any transform size N can be computed and the number of different transform sizes that can be supported (including powers-of-2) is only limited by the size of this parameter memory.
LTE Summary
In the 3rd Generation Partnership Project, Long Term Evolution wireless network protocol, or “LTE” protocol, the uplink departs significantly from the downlink in that it is single channel frequency division multiple access (SC-FDMA, 3GPP TS 36.211 v8.1.0 2007-11). In this case a DFT precedes the IFFT and it is restricted to transform factors taken from the set {2,3,5}. There are 35 different DFT sizes used in the LTE SC-FDMA uplink protocol from 12 to 1296-points with each containing the factor 12. The FFT circuit is required to compute any of these transform sizes at “run-time.”
Architecture
The circuit control uses the well known “row/column factorization” method for computing the transform. Here, the transform size is N=Nr Nc (Nr rows by Nc columns), so Nc Nr-point column DFTs are done, then an N-point twiddle multiplication, and finally Nc Nr -point row DFTs. The column and row DFTs make use of the radix-2 through radix-6 butterflies.
Each column or row transform size is computed using the basic equations and abstract architecture shown in Fig. 1(a). Because each LTE transform of size N contains the factor 12, the architecture uses the value b=6 which defines the left-hand-side (LHS) and right-hand-side (RHS) PE array sizes (Fig. 1(b)). With this choice DFT architectures for b=5,4,3,2 are embedded as well. Then the 35 LTE transform sizes make use of the factorization N=2n3m4p5q6r, where n,m,p,q and r are integers.
Consider the example N=540. Since the implementation consists of 6×6 arrays, it would be most efficient to use the factorization N=540=N3*N4=36*15=62*(3*5) because it makes better use of all the hardware. In this case the processing consists of 15 36-point column DFTs followed by 36 15-point row DFTs. The input Xb has been stored in the input buffers in such a way that it is accessible as a sequence of blocks Xci, i=1..15 of 6×6 column data. Then the 36-point column DFTs are done using the equations (Fig. 1a) with M=36=N1c*N2=N1c*b=6*6 and (B=6). Each Xci enters the array at the bottom of the LHS array as shown below and flows upward with matrix-matrix multiplications performed as shown in Fig. 1(a). As each of these 36-point column DFTs are computed they are multiplied by elements in the 36×15 twiddle matrix W520. During this processing step all PEs are used with 100% efficiency.
After twiddle multiplication by W520 a multiplexor is used to store data for the 15-point row DFTs in a way that they can be accessed as 3×5 data input blocks, Xri, i=1..36, from the internal PE RAMs. In particular each of the 6 PE rows is responsible for storing 6 3×5 blocks of DFT row data in associated internal RAMs. (For the row DFTs not all the LHS/RHS arrays are used.). Rather, the LHS array reads from RAMs in five of the six PE columns to do the 5-point transforms by multiplication of these data blocks by C5. The multiplier array then multiplies these transform values arriving from the LHS array by appropriate elements of a 3×5 twiddle matrix stored in a small ROM. Finally, only 3 PE columns are used on the RHS array to perform all the 3 point transforms. Results are stored in an output buffer.
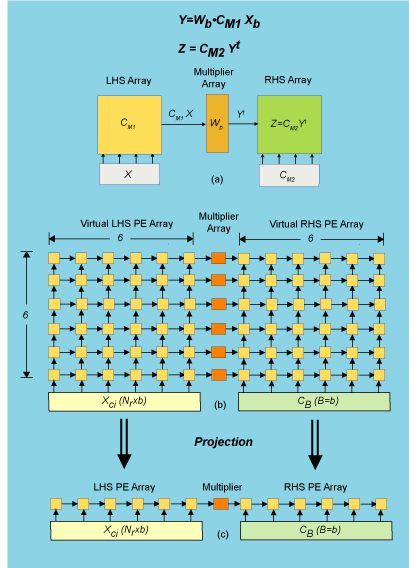
Fig. 1. (a) Basic defining equation and abstract architecture; (b) virtual PE array, where each PE is indicated by the yellow box and contains an adder, multiplier, registers and miscellaneous logic; (c) actual array implementation resulting from projection of the architecture (b) onto a linear array of PEs.
Because 6×6 array sizes would result in operation speeds that far exceed that needed in today’s applications, only a single linear PE row was used for the left-hand-side (LHS) and right-hand-side (RHS) PE arrays. In other words each LHS, RHS and multiplier PE array are considered “virtual” and the linear array shown in Fig. 1(c) emulates the operation of the larger 6×6 arrays. This mapping involves projecting or “collapsing” the columns in the array shown in the Fig. 1(b) onto a single PE in Fig. 1(c). In this linear array there are 6 RAM memories associated with LHS/RHS PEs and a single output buffer RAM. Also, a complex multiplier is used in each LHS/RHS PE.
Performance
Total computational throughput in clock cycles per DFT are shown in the table below.Typical clock speeds are about 400MHz, so the slowest throughput (N=1200-points ) is ~9µsec.Since only one PE row is used to emulate all 6 PE rows in the virtual array (Fig. 1(b)), it is possible to further increase speeds by using more than one. If all 6 PE rows were implemented, the slowest throughput (N=1200-points) would be ~1.5µsec.
| DFT Size N |
Cycles per DFT |
DFT Size N |
Cycles per DFT |
DFT Size N |
Cycles per DFT |
| 1296 | 2592 | 576 | 1154 | 180 | 365 |
| 1200 | 3601 | 540 | 1081 | 144 | 289 |
| 1152 | 3458 | 480 | 962 | 120 | 244 |
| 1080 | 2160 | 432 | 864 | 108 | 221 |
| 972 | 3891 | 384 | 770 | 96 | 200 |
| 960 | 2881 | 360 | 721 | 72 | 149 |
| 900 | 1801 | 324 | 651 | 60 | 124 |
| 864 | 1728 | 300 | 601 | 48 | 102 |
| 768 | 2304 | 288 | 578 | 36 | 36 |
| 720 | 1440 | 240 | 481 | 24 | 24 |
| 648 | 1296 | 216 | 437 | 12 | 12 |
| 600 | 1201 | 192 | 384 |